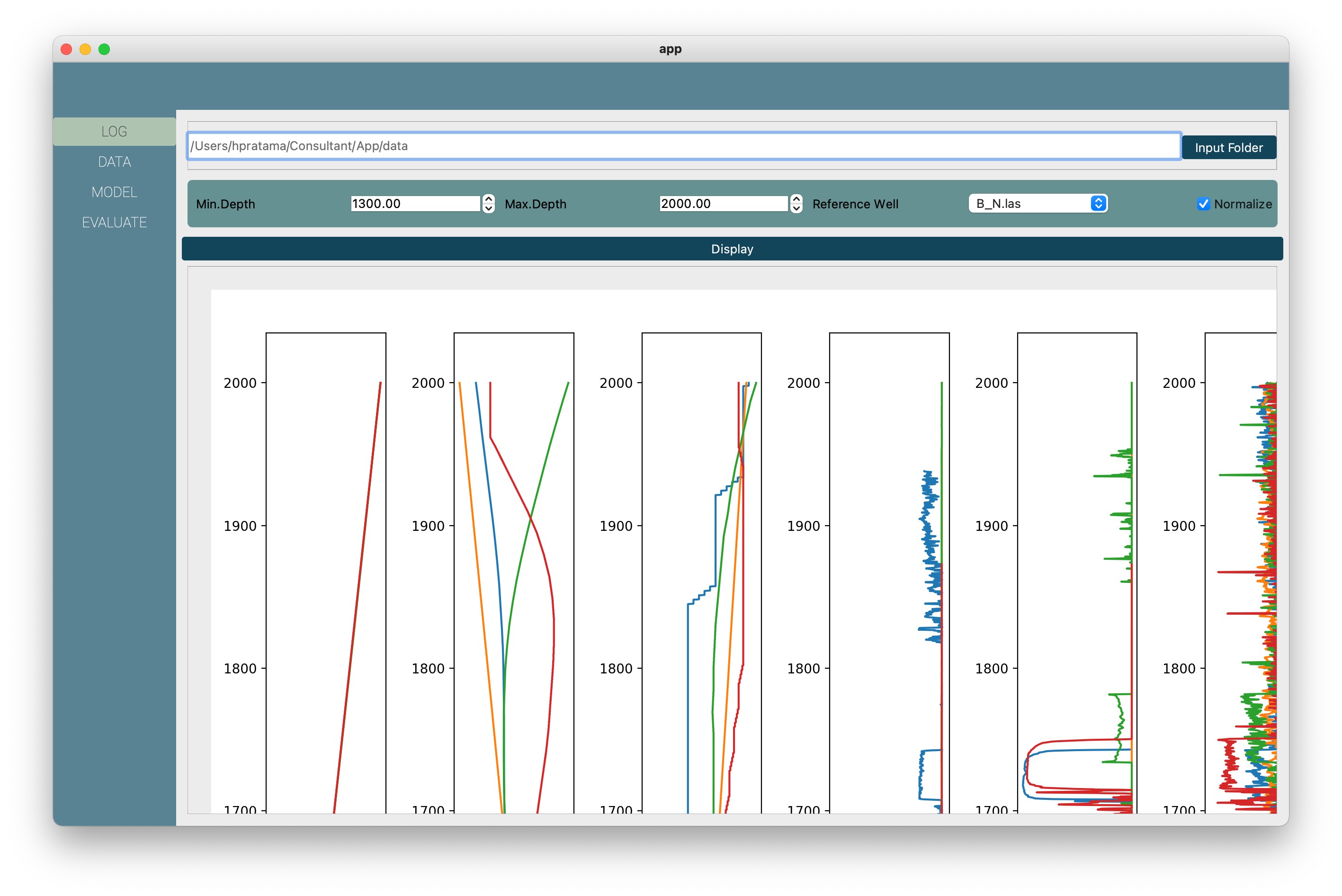
SLog process is simple first select the Output, the log curve you want to predict. Then, select the others log curves input or features. Not sure, which of those logs will be the right input? Don’t worry! You can easily choose and filter the input based on the correlation with the target logs. Also, you can see the missing curve in which depth for each well.
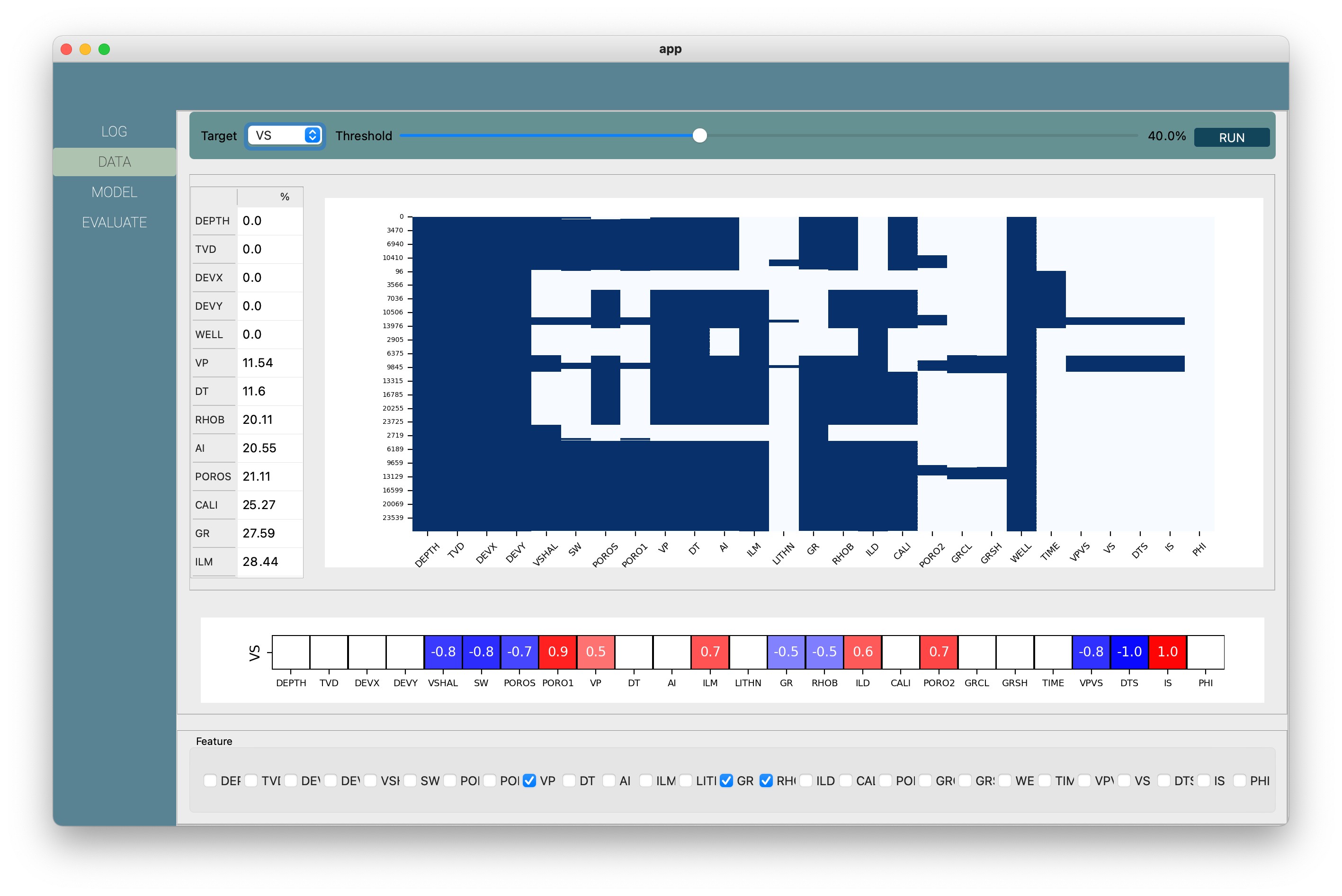
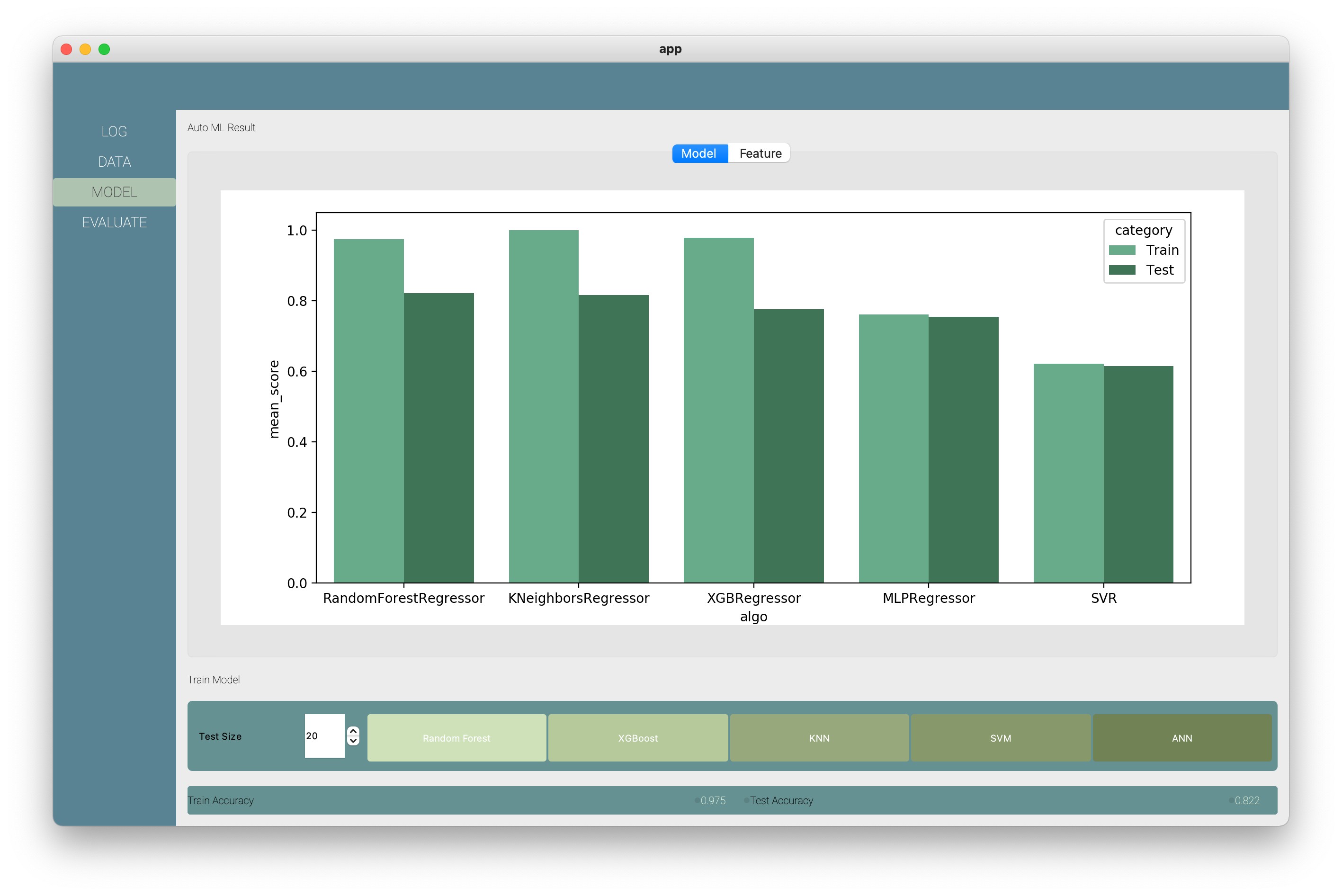
The SLog will train the model based on human expertise. So we, as the petrophysicist, had full control of building those models. You can choose the train and test size, and SLog will run four types of well-known ML algorithms: Random Forest, KNN, SVM, ANN, and Linear Regression, then select the best algorithm from those four algorithms. Another feature that we developed in SLog is you can see the feature’s importance. So you can evaluate the feature selection process more efficiently.
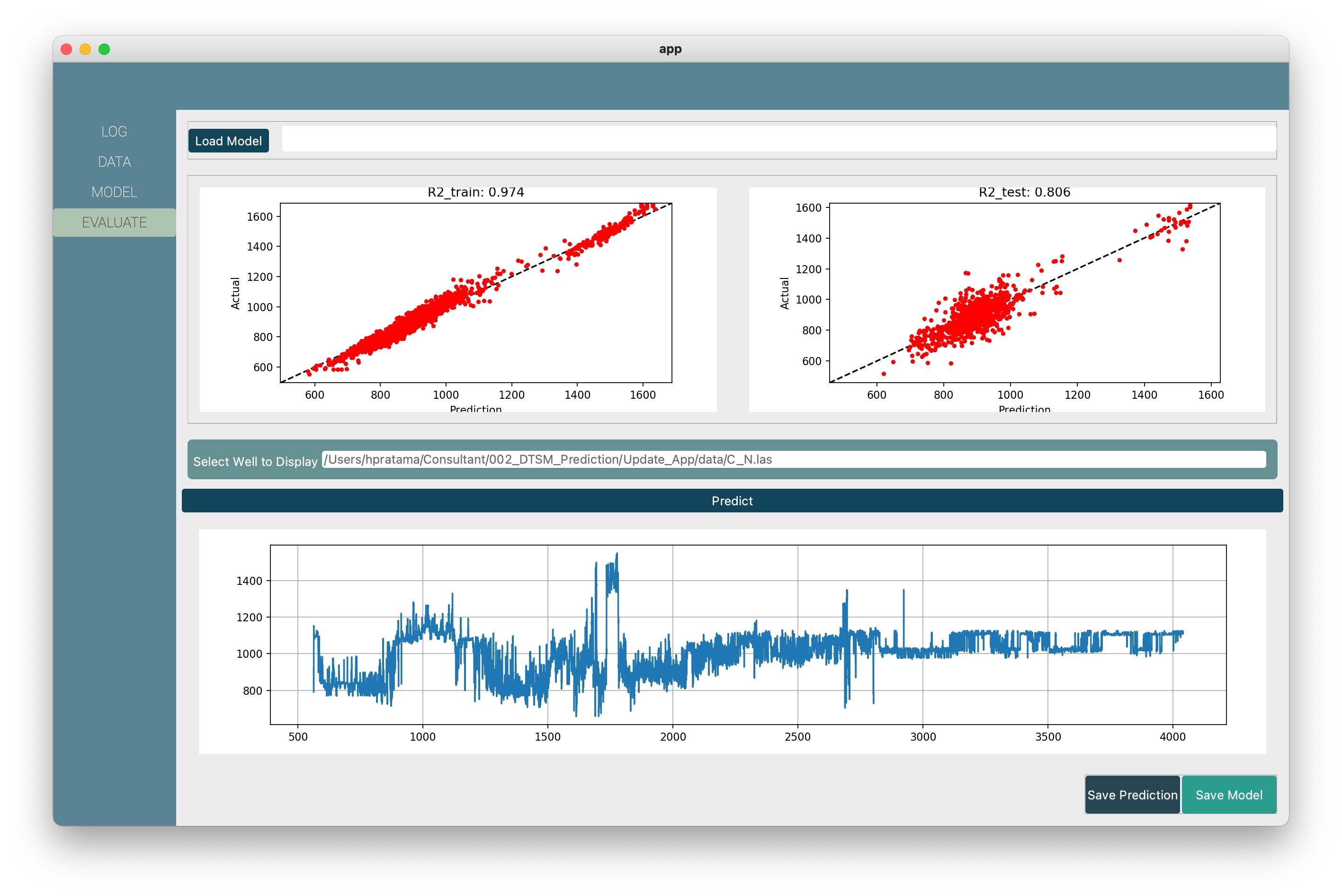
After selecting the best algorithm, we can optimize the selected algorithm by doing hyperparameter tuning. This process is automatically run on the backend of SLog. Another function on SLog that you’d love is a save model function. So, next time you want to predict the log curve on other wells, you just open and load the model. Then, the model will automatically give you the estimation value. Also, you can save the prediction on two different types of format; LAS and .PRN. Lastly, you also can do a normalization, select the interest zone, and display the log curves with these tools.
Skills: Python, Numpy, Pandas, Scikit-learn, lasio, PyQt5